北京超级云计算中心操作训练指南
本人在实验室做深度学习图像领域相关研究,前期使用实验室的设备 2080Ti ,运行时间较慢;跑一轮需要6个小时以上;后来开始使用超算,运行速度比实验室快多了,但超算使用前需要相关配置,使用难度相较于本地会难一点,本文以北京超级云计算中心和 yolov5 训练为例,详细介绍超算的环境安装与计算过程。
一、获取账号
使用超算首先需要的当然是需要有超算的使用权限以及超算的账号了。本文主要以北京超级云计算中心为例。
- 首先在百度、知乎等平台搜索北京超级云计算中心试用,找到申请的表单,提交申请即可。学校教师或学生使用教育网邮箱概率更大哦。
- 申请试用后大约 1~2 天,北超云会依据你留的手机号给你打电话,电话里会沟通一些超算中心试用节点等信息。
- 电话沟通后大于 1~2 天内会收到超算账号开通的邮件,届此获取账号环节结束。
二、安装环境
根据邮件中的网址 https://cloud.blsc.cn/ 与账号密码登陆超算平台网页版,或下载客户端登陆。登陆后界面如下图所示。
2.1 安装系统软件
在运行前需要安装一些必要软件。打开桌面应用中心,找到 ssh、WinScp 等选择并安装。
ssh 用户链接超算账号,执行超算命令。
WinScp 用于查看、上传、下载超算节点的文件。
其他软件按需求安装。
2.2 配置 yolov5 深度学习环境
使用 SSH 链接超算节点后,需要在节点内配置运行环境。
超算节点安装好了一些默认环境,使用 module avail 可查看节点可用的软件列表。
使用 module load anaconda/2020.11 加载 anaconda 环境。
使用 conda creat -n torch110 Python=3.8 创建一个名为 torch110 的 python3.8 的虚拟环境。
使用 module load cuda/11.3 加载 cuda/11.3 环境。
使用 source activate torch110 激活 python 虚拟环境。
使用 conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge 安装 torch 1.10.0 环境,可依据需要自行安装其他 torch 版本环境。
然后使用 WinScp 工具将本地 yolov5 训练文件以及训练数据上传到超算节点的 run 文件夹下。
然后进入 yolov5 文件夹下,执行 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple some-package 安装 yolov5 需要的运行环境。
三、训练数据
3.1 创建 sub.sh 文件
在上传的 run/yolov5 文件夹下新建文件 sub.sh。
在 sub.sh 中填入一下内容:
# sub.sh
# #!/bin/sh
# 加载 anaconda
module load anaconda/2020.11
# 加载 cuda 11.3
module load cuda/11.3
# 激活 python 虚拟环境
source activate torch110
export PYTHONUNBUFFERED=1
# yolov5 python 训练的的命令(此处需要自己依据自己训练的需要进行修改)
python train.py --img 640 --batch 16 --epoch 100 --data dataset/data/voc2007.yaml --cfg dataset/yolov5s_1.yaml --weights weights/yolov5s.pt
3.2 提交训练
使用 ssh 工具进入 sub.sh 根目录中,执行 sbatch --gpus=GPU数量 程序运行脚本 ,例如 sbatch --gpus=1 ./sub.sh 提交需要训练的数据到超算的计算节点。
3.3 查看提交结果
-
查看已提交作业
parajobs

其中,
第一列 JOBID 是作业号,作业号是唯一的。
第二列 PARTITION 是作业运行使用的队列名。
第三列 NAME 是作业名。
第四列 USER 是超算账号名。
第五列 ST 是作业状态,R(RUNNING)表示正常运行,PD(PENDING)表示在排队,CG(COMPLETING)表示正在退出,S 是管理员暂时挂起,CD(COMPLETED)已完成,F(FAILED)作业已失败。只有 R 状态会计费。
第六列 TIME 是作业运行时间。
第七列 NODES 是作业使用的节点数。
第八列 NODELIST(REASON)对于运行作业(R 状态)显示作业使用的节点列表;对于排队作业(PD 状态),显示排队的原因。
-
取消作业
执行scancel 作业ID取消作业scancel 20118812 -
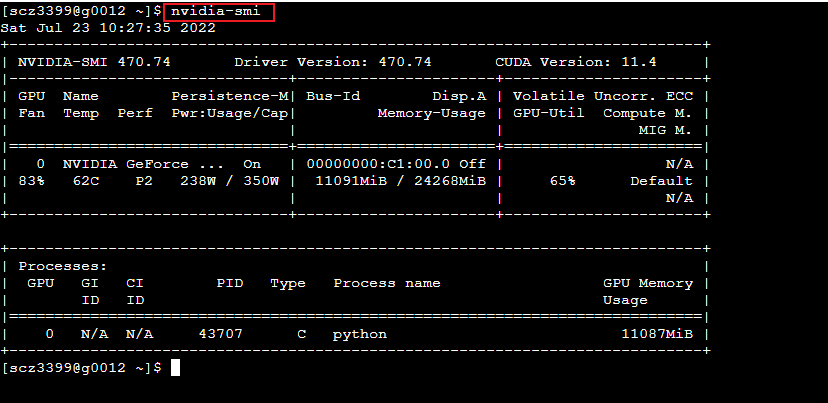
进入计算节点中
使用 ssh 作业节点数 如 ssh g0012 进入当前提交训练的计算节点中,使用 nvidia-smi 可查看当前计算节点的运行情况。
3.4 查看训练结果
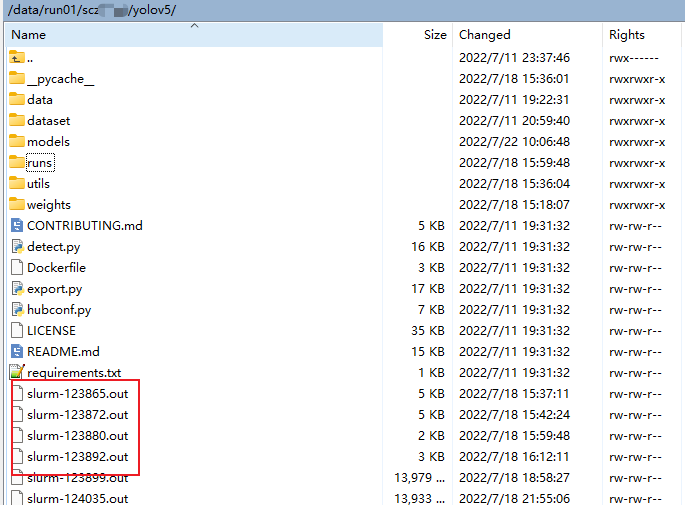
- 训练的全部日志保留在
run/yolov5根目录中名为slurm-XXX.out文件中。 - 训练完成的结果与本地训练一样,存放在
run/yolov5/runs/train中。